

The continued success of my excessively decoupled React SPA architecture

I run the front-end development of a food ordering start-up in the education sector in the UK. I have been working on the front-end of our B2B SaaS SPA SwiftKitchen for two years now (with breaks to build a couple of apps) and even with the product continuing to grow quickly bugs are relatively rare.
I think a large part of this success is because of the architectural decisions made early on. The back-end is a Laravel API and is developed by my colleague completely separately. Let me break down how I went about architecting the site.
I was initially hesitant to write this post, fearing that revealing my grug brained approach to my web app's architecture might undermine my credibility. However, considering the success of the approach, I have decided to share it and perhaps encourage others to adopt this approach if the context is right.
Edit: I recently I found bulletproof react, an architecture repo based on the same priniciples as this post.
Wide vs Deep websites
When I start a new commercial project I have tended to think of websites as wide vs deep.
- Wide apps - The actions being performed by the user are technically quite simple. Viewing tables, filling in forms, running reports. These kinds of apps are very common in enterprise and this is what our app is. Users manage roles, create and adjust menus/prices/availability, assign students to menus and that kind of thing. The most complex parts of the system are drag and drop menu builders and ordering/checkout on the user facing UI. There is no great depth here but there is a large amount of work to do making all of the data visible and modifiable.
- Deep apps - I consider these apps where the interactions the user is doing are complex but the breadth is quite small. Think about something like Obsidian where you are building a complex multimodal interface on top of a node graph structure. Another example might be figma which has collaborative realtime editing of graphical assets. Google Sheets & CodeSandbox are other examples that come to mind.
I wouldn't recommend the approach I have outlined here for deep websites, in this post I am going to talk about wide websites.
Above is our wide website with lots of nav. Mostly variations of tables and forms. These forms can get quite complex, often highly reactive and multimodal.
Quick overview of the stack
This article isn’t about these decisions, but for the record they were chosen after a lot of experimentation and I don’t regret any of them.
- React - industry standard. We chose an SPA because sometimes the database calls are complex and can take a while and it would be nice to keep the UI responsive during those calls. The staff using the software also use it all day so it’s only loaded once and loaded from cache from then on.
- Vite - this used to be webpack from create-react-app but that was deprecated so we migrated to Vite without much fanfare.
- Redux Toolkit - Redux is a productivity killer without this library and a dream state management system with it. I won't go without it now. We also use Redux Toolkit Query for most of the queries (some simple GETs live in components).
- Tailwind CSS - If I can avoid it, I’m never going back to regular BEM CSS classes. I can see why people who havn’t used it for extended periods are skeptical but its popularity is earned.
- React Router - Industry standard front-end routing, no complaints.
Folder & File Structure
I decided to try and keep our folder structure as flat as possible, we have the following folders:
- App - for the entry point of the react app, I also put the root of the redux store here.
- Common - for the few shared components like the Nav and some Skeletons
- Constants - Contains routes and endpoints and some more important allergen constants etc
- Features - In this folder we separate our app by sections within the app. Some examples are:
- Transactions - In here lies the code for the transitions part of the app, accessible from ‘Transactions’ in the nav
- MenuSchedules - In here lies the code for the Menu Schedules part of the app, accessible from ‘Menu Schedules’ in the nav
- etc
- Utils - Helper functions and utilities live in here.
Within the features folder we have a folder per feature. Each feature folder contains the components related to that feature and also the slice of the store related to that feature. Every part of the website has its own slice in the store. The way I name the files within these folders is also quite unconventional - I name based on the nesting of the React JSX. Let me give a simple example. A very simple part of the site is adding new locations to a company (in our context this is schools served by a catering company).
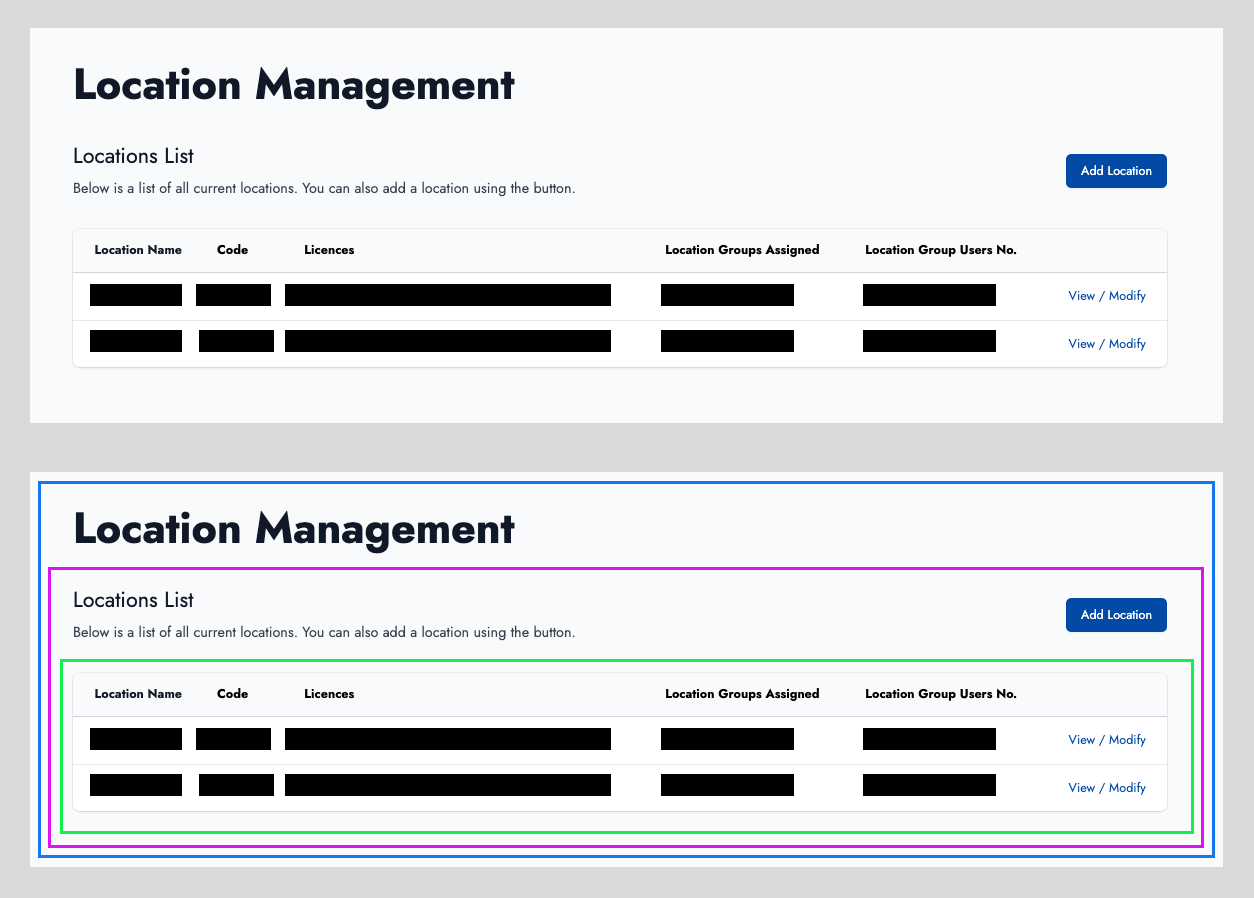
You can see in the bottom image that the green box is inside the pink box which is inside the blue box. I name the components by appending what the JSX represents to the end of the name of its parent. In the image above these components are named:
- Blue - Locations.jsx
- Purple - LocationsView.jsx
- Green - LocationsViewTable.jsx
This is one of the simplest examples of this naming convention but it can get quite silly. For example some real files in the codebase:
- ReportsViewFormUnassignedConsumersReportParams.jsx
- DirectDebitViewCreateLocationDynamicSelect.jsx
- MenuTermsLocationOutletsDynamicSelect.jsx
The cool thing about this naming convention though is that you probably know exactly what you’re going to find in these files. The naming is incredible clear. Another advantage is that you can look at the files names and get a sense of how a page is structured. This means that you if need to make a change to a page you can look at the page and the names of the files and very quickly figure out where the change needs to happen. The fact that these names are long is unimportant when your IDE imports them or you anyway, so you’re very rarely typing the long names.
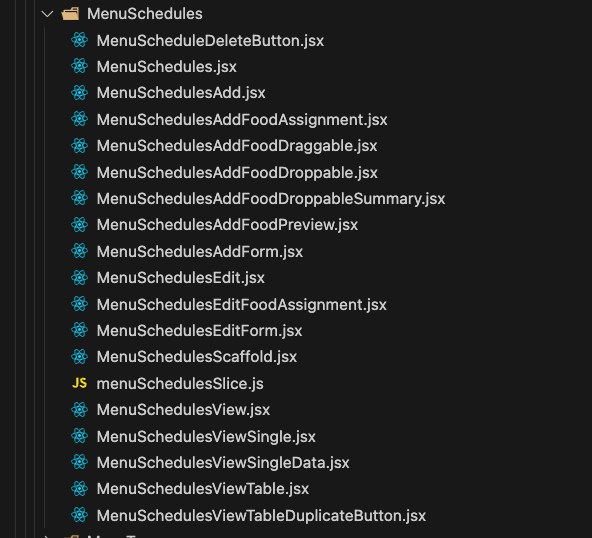
This is the layout of the Menu Schedules part of the website, you can likely guess the structure of the pages and what is contained within each file at a glance without any context of the product.
Additionally when you open these files you can see the styling immediately in the JSX because we use tailwind. The front end is an open book waiting to be read.
The obvious disadvantage of naming components this way is that it doesn’t allow component re-use, which leads me onto the most controversial part. That’s the point.
Almost complete component decoupling
We use tailwind all of our styling so all of the styling code is contained within our component code in the JSX classNames. When we build a new feature, we create a new directory for the feature and start taking similar components from other parts of the website (within reason) and go from there. I know this sounds like a terrible anti pattern but hear me out.
By doing this every feature is completely decoupled from every other feature. This means that so long as you don’t touch the code for a feature it will continue to work. There has never been a situation where changing the code in one part of the system unexpectedly breaks another part of the system. We never have to deal with complex components that have a lot of parameters/flags because ‘x part of the system needed this feature’ and ‘y part of the system needed another feature’ and they were both using the same component. This keeps the front end code very robust.
The frustrating part of writing this blog post is that I swear I got the idea from a talk by a Facebook engineer but my PKM has severely let me down because I cannot find it.
We do have some shared components, for example we use a library for searchable multi select boxes, we share some simple Skeleton components and a couple of minor things but generally it is all completely decoupled. The rule of thumb is that if its to enhance the usability of an existing HTML element then it's close enough to the bone to be a shared component.
The only place that we break the complete decoupling is with some shared state, for example in the ordering side of the app, many different components can access the wallet balance. Redux toolkit makes this a breeze though with its useSelector hook and immutable references.
Another advantage to this decoupling is that when others need to drop into the codebase add a new feature, they can be quite confident that they arn't causing unexpected breaking changes due to interdependent code.
Refactoring
A large disadvantage of this structure is the manpower needed for styling refactors. In terms of functionality refactoring is quite nice, the complete decoupling means you don’t have to worry about breaking other features if you want to refactor a different one but styling can require a bit of manpower. Say you want to change all of your page headers to the right instead of the left you would have to go into every file that contained that header and modify the tailwind for those headers. It is work. Fortunately this isn’t the biggest deal for me, we are an enterprise application, mostly tables and forms - the styles of these don’t need to change often (once every 15 years) and its likely rewrites would happen in that time anyway. I’m not convinced its always more work though, if you weren't using tailwind and were using shared CSS classes it would take enormous effort to find all instances of those CSS classes with the system and make sure that nothing is broken.
What I would do differently if I started again
I would probably use TypeScript.
When we launched it seemed like needless complexity and it sort of was. A small percentage of the bugs we have found in the last 2 years would have been solved if we had used TypeScript. The reason I think it would be good now is because of the way the API is set up.
Almost all of our bugs occur at the data boundaries (like most applications) where the API response isn’t what the front end is expecting or the SPA request isn’t what the API is requesting. The back end developer at our team recently moved the entire API to use the OpenAPI specification document using Swagger. I could now use that OpenAPI spec to create request and response types automatically for all API communication using https://www.npmjs.com/package/openapi-typescript. This would help eliminate the source of most of the bugs we encounter, this advantage wasnt clear at the start of the project but now it looks like the best option.
I might still try the mammoth task of porting everything to TypeScript and if I do I will start with all the OpenAPI generated types and build out from there.
Thanks for reading.
You can find me on X/Twitter if you want @simonharrisco